Estimating predictive models
David Kepplinger
2026-01-27
Source:vignettes/computing_adapense.Rmd
computing_adapense.RmdIn this guide we will estimate predictive models by means of robust
adaptive PENSE estimates for high-dimensional linear regression. These
estimates can tolerate up to 50% of contamination, i.e., the adaptive
PENSE estimates are reliable even if up to half the observations in the
data set contain anomalous values. Computing adaptive PENSE estimates
with data-drive hyperparameter selection is implemented in the function
adapense_cv() in the pense package.
While the following guide computes adaptive PENSE estimates, the
steps are analogous for other estimates implemented in the pense
package: non-adaptive PENSE estimates and regularized M-estimates.
Non-adaptive PENSE estimates (computed by pense_cv()) are
typically better at identifying all relevant predictors than adaptive
PENSE. However, this comes at the price of often including a large
number of irrelevant predictors as well. Regularized M-estimates
(computed by pensem_cv()) can be more accurate than either
PENSE or adaptive PENSE estimates, but may be unreliable in presence of
highly detrimental contamination, and require a pre-determined estimate
of the residual scale.
Computing adaptive PENSE estimates
First we need to load the pense package:
Computing robust, regularized estimates for high-dimensional linear regression models can take a long time. To save time, many steps can be done in parallel. If your computer has more than 1 CPU core, you can harness more computing power by creating a cluster of R processes:
library(parallel)
# If you don't know how many CPU cores are available, first run `detectCores(logical = FALSE)`
cluster <- makeCluster(2)This guide uses the following simulated data with 50 observations and 40 available predictors. The error distribution is a heavy-tailed t-distribution and only the first 3 predictors are truly relevant for predicting the response y:
set.seed(1234)
x <- matrix(rweibull(50 * 40, 2, 3), ncol = 40)
y <- 1 * x[, 1] - 1.1 * x[, 2] + 1.2 * x[, 3] + rt(nrow(x), df = 2)To make the scenario more realistic, let’s add some contamination to the response value of the first 3 observations and to some predictors:
Step 1: Computing the estimates
The first step is to compute adaptive PENSE estimates for a fixed
value for hyper-parameter alpha and many different
penalization levels (hyper-parameter lambda). The
adapense_cv() function automatically determines a grid of
penalization levels, with parameter nlambda= controlling
the number of different penalization levels to be used (default 50). We
are going to choose the penalization level which leads to a good balance
between prediction accuracy and model size. The pense package can
automatically evaluate prediction accuracy of the adaptive PENSE
estimates via robust information-sharing cross-validation (RIS-CV;
Kepplinger & Wei 2025).
In its simplest form, computing adaptive PENSE estimates and estimating their prediction accuracy is done with the code below. Here, prediction accuracy is estimated via 5-fold RIS-CV, replicated 3 times:
set.seed(1234)
fit_075 <- adapense_cv(x, y, alpha = 0.75, cv_k = 5, cv_repl = 3, cl = cluster)You should always set a seed prior to computing adaptive PENSE or PENSE estimates to ensure reproducibility of the internal cross-validation.
By default, adaptive PENSE estimates are computed with a breakdown
point of ~25% and Tukey’s bisquare \rho
function. This means, the estimates are reliable if up to 25% of
observations contain arbitrary contamination. If you suspect that a
larger proportion of observations may be affected by contamination, you
can increase the breakdown point of the estimates with argument
bdp= to up to 50%. Note, however, that a higher breakdown
point also leads to less accurate estimates. The package also supports
the “optimal” \rho function (Maronna et
al., 2018, Section 5.8.1). To choose a different \rho function, alter the
mscale_opts argument:
set.seed(1234)
fit_075_mopt <- adapense_cv(x, y, alpha = 0.75, cv_k = 5, cv_repl = 3, cl = cluster,
mscale_opts = mscale_algorithm_options(rho = "mopt"))Step 2: Assessing prediction performance
The plot() function for the object fit_075
shows the estimated prediction accuracy for all fitted models.
plot(fit_075)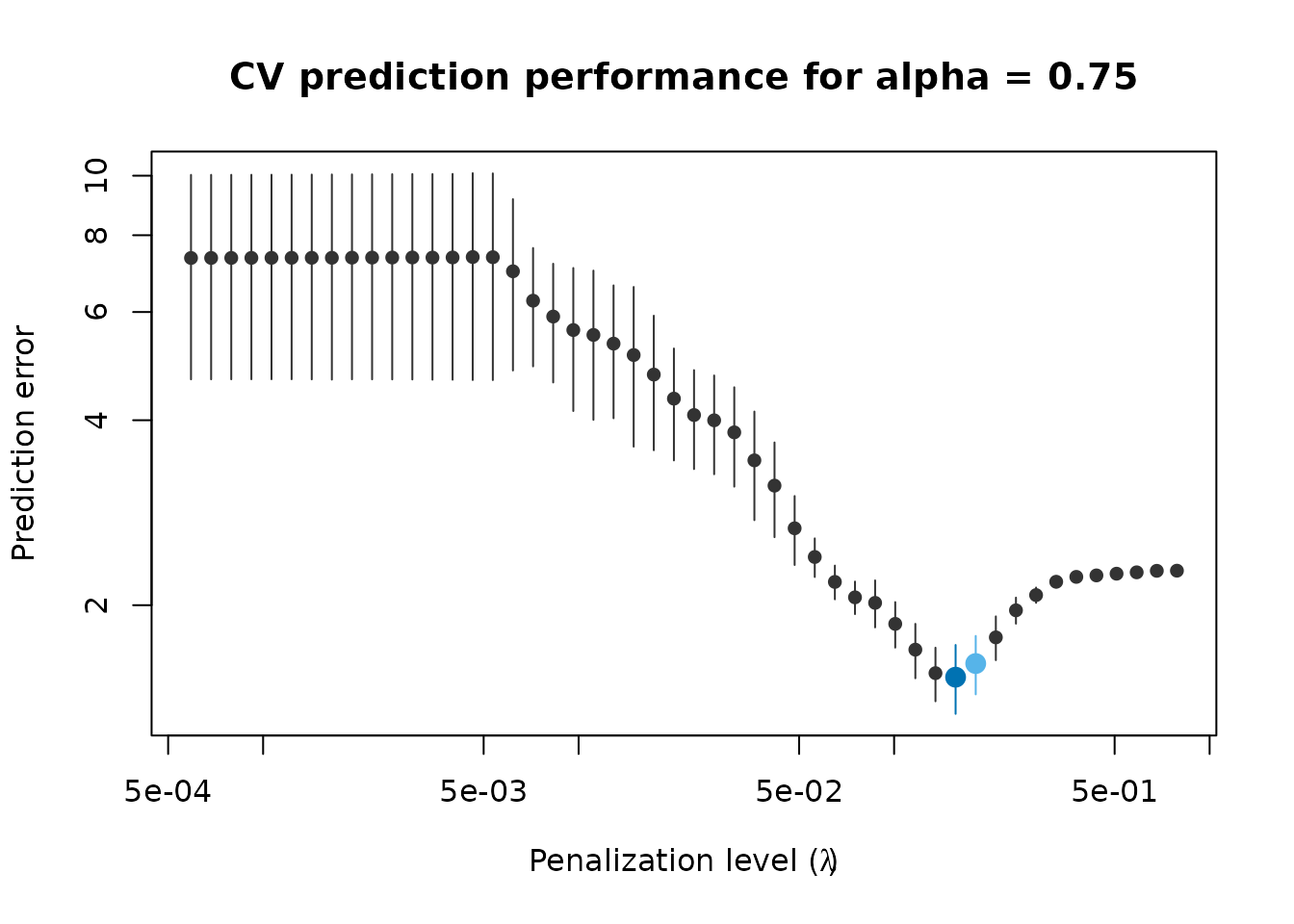
Estimated prediction accuracy using 3 replications of 5-fold CV.
The plot shows the estimated scale of the prediction error for all 50
models. The penalization level leading to the best prediction
performance is highlighted by a dark blue dot. If more than one CV
replication was performed, the plot also shows a light blue dot, marking
the most parsimonious model with prediction performance
“indistinguishable” from the best model. The plot uses the
“one-standard-error” rule using the minimum average scale of the
prediction error plus 1 standard error of this estimated scale. You can
adjust this rule to the “m-standard-error” with
plot(fit_075, se_mult = m), where m is any
positive number (e.g., m=2).
The accuracy of the estimate can be improved by increasing the number of CV replications. The more CV replications, the more accurate the estimates of prediction accuracy, but the longer the computing time. If we repeat step #1, but with 10 CV replications instead of 3, we get a more stable evaluation of prediction performance:
set.seed(1234)
fit_075 <- adapense_cv(x, y, alpha = 0.75, cv_k = 5, cv_repl = 10, cl = cluster)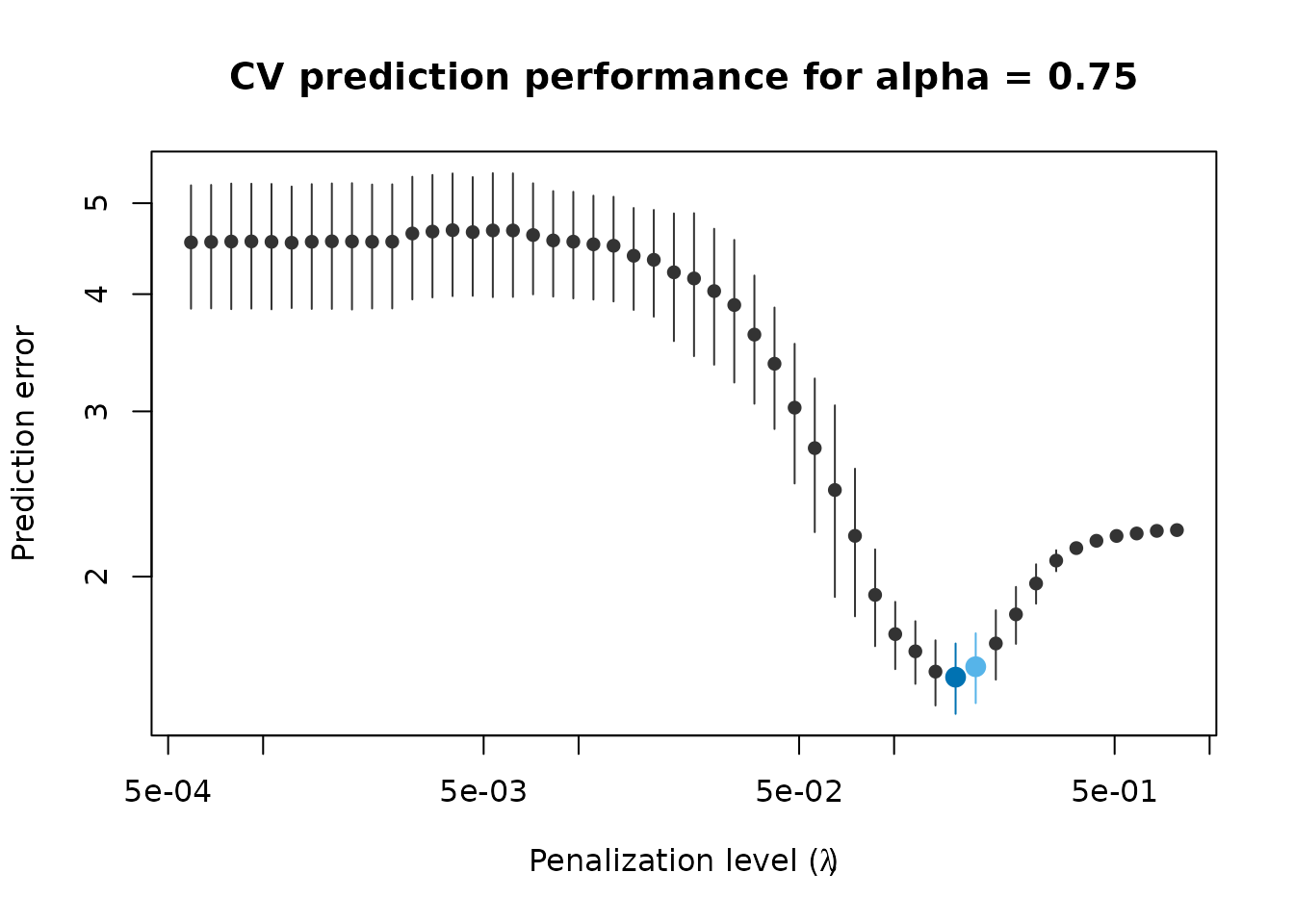
Estimated prediction accuracy using 10 replications of 5-fold CV.
Step 3: Extracting coefficients
Once we are happy with the stability of the estimated prediction performance, we can extract summary information from the predictive model with
summary(fit_075)
#> Adaptive PENSE fit with prediction performance estimated by 10 replications of
#> 5-fold ris cross-validation.
#>
#> 6 out of 40 predictors have non-zero coefficients:
#>
#> Estimate
#> (Intercept) 0.89610051
#> X1 0.66483511
#> X2 -0.73465818
#> X3 0.55847642
#> X5 0.03486861
#> X29 0.03892034
#> X39 -0.01298290
#> ---
#>
#> Hyper-parameters: lambda=0.1566381, alpha=0.75, exponent=1This model corresponds to the model with smallest scale of the prediction error (the blue dot in the plot above). There are a total of 6 predictors in the model. If you think a sparser model may be more appropriate for your application, you can also apply the m-standard-error rule as in the plots. The default, the one-standard-error rule leads to the following predictive model:
summary(fit_075, lambda = "se", se_mult = 1)
#> Adaptive PENSE fit with prediction performance estimated by 10 replications of
#> 5-fold ris cross-validation.
#>
#> 4 out of 40 predictors have non-zero coefficients:
#>
#> Estimate
#> (Intercept) 1.28199718
#> X1 0.56993574
#> X2 -0.68590414
#> X3 0.46982332
#> X5 0.02356945
#> ---
#>
#> Hyper-parameters: lambda=0.1814144, alpha=0.75, exponent=1In this fit, only 4 out of the 40 predictors are relevant, including
the 3 truly relevant predictors. But maybe different values for
hyper-parameters alpha and exponent lead to
even better prediction?
Step 4: Exploring different hyper-parameters
The choice for hyper-parameters alpha and
exponent (which was kept at its default value of 1) are
rather arbitrary. The effects of these two hyper-parameters on the
estimates are in general less pronounced than of the penalization level.
But you may still want to explore different values for
alpha and exponent.
While alpha=0.75 is a good value for many applications,
alpha=1 may also be of interest, particularly in
applications where correlation between predictors is not an issue. In
applications with high correlation between predictors, lower values of
alpha (e.g., alpha=0.5) may lead to more
stability in variable selection.
The hyper-parameter exponent generally has an effect on
the sparsity of the models. With higher values for
exponent, typically only predictors with the largest (in
absolute magnitude) standardized coefficients will be non-zero. While
this helps to screen out many or most of the truly irrelevant, it also
risks missing some of the truly relevant predictors.
Let us compute adaptive PENSE estimates for different values of
hyper-parameters alpha and exponent. In the
code below, this is done for two values: alpha=0.75 and
alpha=1 as well as exponent=1 and
exponent=2.
set.seed(1234)
fit_exp_1 <- adapense_cv(x, y, alpha = c(0.75, 1), exponent = 1, cv_k = 5, cv_repl = 10, cl = cluster)
set.seed(1234)
fit_exp_2 <- adapense_cv(x, y, alpha = c(0.75, 1), exponent = 2, cv_k = 5, cv_repl = 10, cl = cluster)Note that we set the seed before each call to
adapense_cv(). This is again to ensure reproducibility of
the CV, but also to make the estimated prediction performance more
comparable across different values of the exponent
hyper-parameter.
After checking that the RIS-CV prediction performance of the fitted
models is smooth enough to reliably select the penalization level, we
can compare all the estimates. For this, the package includes the
function prediction_performance(), which extracts and
prints the prediction performance of all given objects:
prediction_performance(fit_exp_1, fit_exp_2)
#> Prediction performance estimated by cross-validation:
#>
#> Model Estimate Std. Error Predictors alpha exp.
#> 1 fit_exp_2 1.440873 0.09734518 4 1.00 2
#> 2 fit_exp_2 1.451103 0.09829709 7 0.75 2
#> 3 fit_exp_1 1.553635 0.13786022 4 1.00 1
#> 4 fit_exp_1 1.562786 0.13463294 6 0.75 1Here we see the combination of hyper-parameters alpha=1
and exponent=2 (in object fit_exp_2) leads to
the best prediction accuracy. We can also compare sparser models with
similar prediction performance:
prediction_performance(fit_exp_1, fit_exp_2, lambda = 'se')
#> Prediction performance estimated by cross-validation:
#>
#> Model Estimate Std. Error Predictors alpha exp.
#> 1 fit_exp_2 1.498405 0.08330122 3 0.75 2
#> 2 fit_exp_2 1.517282 0.11277732 3 1.00 2
#> 3 fit_exp_1 1.603343 0.13706756 4 0.75 1
#> 4 fit_exp_1 1.628196 0.14851228 3 1.00 1If we are interested in even sparser models, we can increase the tolerance level to, for instance, 2 standard errors:
prediction_performance(fit_exp_1, fit_exp_2, lambda = 'se', se_mult = 2)
#> Prediction performance estimated by cross-validation:
#>
#> Model Estimate Std. Error Predictors alpha exp.
#> 1 fit_exp_2 1.561675 0.1044480 3 0.75 2
#> 2 fit_exp_2 1.607036 0.1202396 3 1.00 2
#> 3 fit_exp_1 1.754913 0.1452938 3 1.00 1
#> 4 fit_exp_1 1.823087 0.1272765 4 0.75 1This relaxation now leads to the combination of hyper-parameters
alpha=0.75 and exponent=2 and only 3 relevant
predictors. We can see that the estimated coefficients and estimated
relevant predictors are close to the truth:
summary(fit_exp_2, alpha = 0.75, lambda = 'se')
#> Adaptive PENSE fit with prediction performance estimated by 10 replications of
#> 5-fold ris cross-validation.
#>
#> 3 out of 40 predictors have non-zero coefficients:
#>
#> Estimate
#> (Intercept) 1.1507826
#> X1 0.7821125
#> X2 -0.8275043
#> X3 0.4945724
#> ---
#>
#> Hyper-parameters: lambda=0.02282, alpha=0.75, exponent=2Using different measures of prediction performance
By default, adapense_cv() uses the robust information
sharing (RIS) cross-validation procedure and the corresponding weighted
mean squared prediction error to estimate prediction accuracy. The user
can choose to use standard CV via
adapense_cv(cv_type = "naive"), which also enables the user
to then choose different metrics of prediction performance. The package
supports the tau-scale estimate of the prediction error (default for
naïve CV), the mean absolute prediction error
(cv_metric = "mape") or the classical root mean squared
prediction error (cv_metric = "rmspe"). You should,
however, not use the RMSPE to evaluate prediction performance in the
potential presence of contamination. Robust methods are not designed to
predict contaminated observations well and the RMSPE may be artificially
inflated by poor prediction of a few contaminated response values. You
can also specify your own function which takes as input the vector of
prediction errors and returns a single number, measuring the prediction
performance. For example, to use the mean absolute prediction
error, you would write
mae <- function (prediction_errors) {
mean(abs(prediction_errors))
}
set.seed(1234)
fit_075_mae <- adapense_cv(x, y, alpha = 0.75, cv_k = 5, cv_repl = 5,
cl = cluster, cv_type = "naive", cv_metric = mae)A matrix with estimates of the prediction performance are accessible
as slot $cvres in the object returned by
adapense_cv(). The rows correspond to the different
penalization levels.
References
- D. Kepplinger and S. Wei, “Information sharing for robust and stable cross-validation,” Technometrics, 2025, doi: 10.1080/00401706.2025.2540970.
- R. A. Maronna, D. R. Martin, V. J. Yohai, and M. Salibián-Barrera, Robust Statistics: Theory and Methods (with R). in Wiley Series in Probability and Statistics. Hoboken, NJ: John Wiley & Sons, Inc., 2019.