Extract coefficients from an adaptive PENSE (or LS-EN) regularization path with hyper-parameters chosen by cross-validation.
Usage
# S3 method for class 'pense_cvfit'
coef(
object,
alpha = NULL,
lambda = "min",
se_mult = 1,
sparse = NULL,
standardized = FALSE,
...
)Arguments
- object
PENSE with cross-validated hyper-parameters to extract coefficients from.
- alpha
Either a single number or
NULL(default). If given, only fits with the givenalphavalue are considered. Iflambdais a numeric value andobjectwas fit with multiple alpha values and no value is provided, the first value inobject$alphais used with a warning.- lambda
either a string specifying which penalty level to use (
"min","se","{m}-se") or a single numeric value of the penalty parameter. See details.- se_mult
If
lambda = "se", the multiple of standard errors to tolerate.- sparse
should coefficients be returned as sparse or dense vectors? Defaults to the sparsity setting of the given
object. Can also be set tosparse = 'matrix', in which case a sparse matrix is returned instead of a sparse vector.- standardized
return the standardized coefficients.
- ...
currently not used.
Value
either a numeric vector or a sparse vector of type
dsparseVector
of size \(p + 1\), depending on the sparse argument.
Note: prior to version 2.0.0 sparse coefficients were returned as sparse matrix of
type dgCMatrix.
To get a sparse matrix as in previous versions, use sparse = 'matrix'.
Hyper-parameters
If lambda = "{m}-se" and object contains fitted estimates for every penalization
level in the sequence, use the fit the most parsimonious model with prediction performance
statistically indistinguishable from the best model.
This is determined to be the model with prediction performance within m * cv_se
from the best model.
If lambda = "se", the multiplier m is taken from se_mult.
By default all alpha hyper-parameters available in the fitted object are considered.
This can be overridden by supplying one or multiple values in parameter alpha.
For example, if lambda = "1-se" and alpha contains two values, the "1-SE" rule is applied
individually for each alpha value, and the fit with the better prediction error is considered.
In case lambda is a number and object was fit for several alpha hyper-parameters,
alpha must also be given, or the first value in object$alpha is used with a warning.
See also
Other functions for extracting components:
coef.pense_fit(),
predict.pense_cvfit(),
predict.pense_fit(),
residuals.pense_cvfit(),
residuals.pense_fit()
Examples
# Compute the PENSE regularization path for Freeny's revenue data
# (see ?freeny)
data(freeny)
x <- as.matrix(freeny[ , 2:5])
regpath <- pense(x, freeny$y, alpha = 0.5)
plot(regpath)
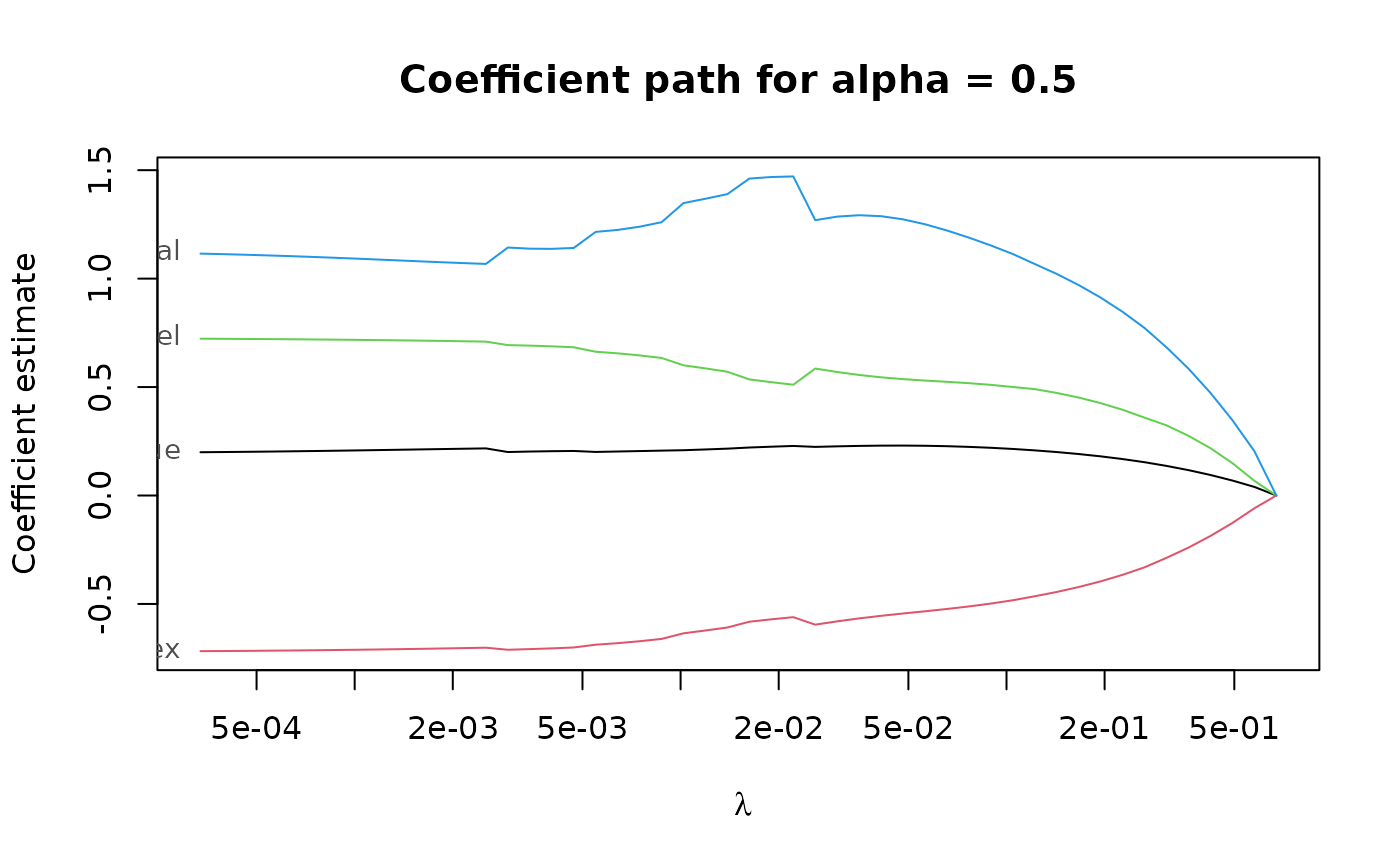 # Extract the coefficients at a certain penalization level
coef(regpath, lambda = regpath$lambda[[1]][[40]])
#> (Intercept) lag.quarterly.revenue price.index
#> -6.5082299 0.2510560 -0.6879670
#> income.level market.potential
#> 0.7090986 0.9409940
# What penalization level leads to good prediction performance?
set.seed(123)
cv_results <- pense_cv(x, freeny$y, alpha = 0.5,
cv_repl = 2, cv_k = 4)
plot(cv_results, se_mult = 1)
# Extract the coefficients at a certain penalization level
coef(regpath, lambda = regpath$lambda[[1]][[40]])
#> (Intercept) lag.quarterly.revenue price.index
#> -6.5082299 0.2510560 -0.6879670
#> income.level market.potential
#> 0.7090986 0.9409940
# What penalization level leads to good prediction performance?
set.seed(123)
cv_results <- pense_cv(x, freeny$y, alpha = 0.5,
cv_repl = 2, cv_k = 4)
plot(cv_results, se_mult = 1)
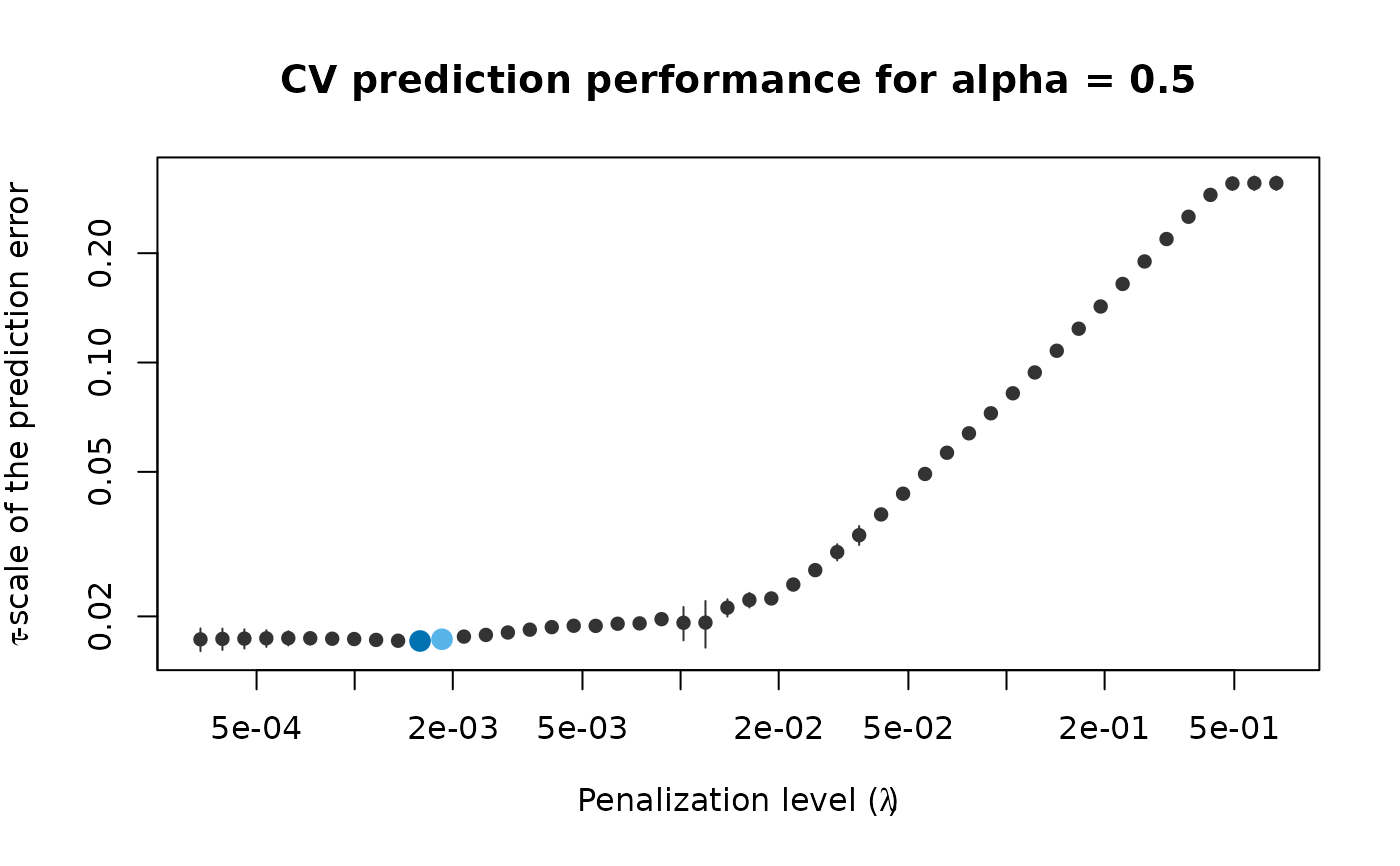 # Print a summary of the fit and the cross-validation results.
summary(cv_results)
#> PENSE fit with prediction performance estimated by 2 replications of 4-fold ris
#> cross-validation.
#>
#> 4 out of 4 predictors have non-zero coefficients:
#>
#> Estimate
#> (Intercept) -4.7921541
#> X1 0.3338834
#> X2 -0.6140406
#> X3 0.6954769
#> X4 0.7316339
#> ---
#>
#> Hyper-parameters: lambda=0.0003364066, alpha=0.5
# Extract the coefficients at the penalization level with
# smallest prediction error ...
coef(cv_results)
#> (Intercept) lag.quarterly.revenue price.index
#> -4.7921541 0.3338834 -0.6140406
#> income.level market.potential
#> 0.6954769 0.7316339
# ... or at the penalization level with prediction error
# statistically indistinguishable from the minimum.
coef(cv_results, lambda = '1-se')
#> (Intercept) lag.quarterly.revenue price.index
#> -11.4754472 0.2265866 -0.5739724
#> income.level market.potential
#> 0.5417608 1.3768215
# Print a summary of the fit and the cross-validation results.
summary(cv_results)
#> PENSE fit with prediction performance estimated by 2 replications of 4-fold ris
#> cross-validation.
#>
#> 4 out of 4 predictors have non-zero coefficients:
#>
#> Estimate
#> (Intercept) -4.7921541
#> X1 0.3338834
#> X2 -0.6140406
#> X3 0.6954769
#> X4 0.7316339
#> ---
#>
#> Hyper-parameters: lambda=0.0003364066, alpha=0.5
# Extract the coefficients at the penalization level with
# smallest prediction error ...
coef(cv_results)
#> (Intercept) lag.quarterly.revenue price.index
#> -4.7921541 0.3338834 -0.6140406
#> income.level market.potential
#> 0.6954769 0.7316339
# ... or at the penalization level with prediction error
# statistically indistinguishable from the minimum.
coef(cv_results, lambda = '1-se')
#> (Intercept) lag.quarterly.revenue price.index
#> -11.4754472 0.2265866 -0.5739724
#> income.level market.potential
#> 0.5417608 1.3768215